MongoDB Indexes: Types, Peculiarities, and Best Practices
Understand how MongoDB indexes work, the different types available, best practices, and common mistakes that impact query performance. An essential guide to optimizing your collections and speeding up your applications.

Introduction
Indexes in MongoDB are data structures that support efficient query execution by limiting the number of documents the database must scan. Without proper indexes, queries can result in full collection scans, leading to high CPU usage, memory strain, and sluggish performance. In this article you will see:
- => Indexers type
- => Best Practices and Some Important Points
- => Simple Benchmark: With vs. Without Indexes
📋 Indexers type
1. Standard Index (B-tree)
This is automatically created on the _id field in every MongoDB collection. It ensures uniqueness and supports fast lookups.
db.collection.find({ _id: ObjectId("...") })2. Compound Indexes
Indexes that include multiple fields. The order of fields in the index is crucial and affects which queries can use the index.
db.collection.createIndex({ age: 1, name: 1 })✅ Efficient usage:
db.collection.find({ age: 30, name: "Carlos" })❌ Inefficient (index not used):
db.collection.find({ name: "Carlos" })3. Multikey Index
Used when indexing fields that contain arrays. MongoDB creates index entries for each element in the array.
db.collection.insertOne({ tags: ["nodejs", "mongodb", "backend"] })
db.collection.createIndex({ tags: 1 })Note: Be cautious with very large arrays — they may cause index bloat and degrade performance.
4. Text Index
Supports full-text search on string content.
db.collection.createIndex({ description: "text" })
db.collection.find({ $text: { $search: "mongodb indexes" } })Peculiarities:
- Only one text index per collection.
- Cannot be directly combined with other fields in a compound index.
5. Hashed Index
Used for equality matches. Not suitable for range queries or sorting.
db.collection.createIndex({ email: "hashed" })Commonly used in sharded collections for data distribution.
📌 Best Practices and Some Important Points
- Use
.explain("executionStats")to check index usage: - Index fields used in filtering, sorting, and joins.
- Avoid redundant or unused indexes.
- Monitor with:
db.collection.getIndexes()
db.collection.stats()=> Understanding Cardinality and Index Composition
Cardinality refers to the number of distinct values a field can have. Understanding cardinality helps determine whether an index will be effective:
- High-cardinality fields (e.g.,
cpf,email,_id) often result in highly selective and efficient indexes. - Low-cardinality fields (e.g.,
active: true,status: "pending") are less useful when indexed alone, as many documents share the same value.
=> Two Simple Indexes vs. One Compound Index
Suppose you frequently run queries like:
db.companies.find({ domain: "test.com", name: "APP One" })✅ Better solution: a compound index that covers the entire query:
db.companies.createIndex({ domain: 1, name: 1 })❌ A common mistake is to create two separate indexes:
db.companies.createIndex({ domain: 1 })
db.companies.createIndex({ name: 1 })- Reduces read costs.
- Improves selectivity by combining two fields.
- May result in a covered index if the projection includes only
domain,name, and_id.
⚠️ Note: The compound index will only be used if the query respects the order of fields in the index definition.
=> Practical Tip
Use .explain("executionStats") to verify index usage:
db.companies.find({ domain: "test.com", name: "APP One" }).explain("executionStats")Common Mistakes
- ❌ Creating too many unnecessary indexes — increases write cost and storage.
- ❌ Indexing deeply nested arrays — can cause index explosion.
- ❌ Indexing high-cardinality, low-selectivity fields — poor performance benefit.
- ❌ Not testing queries with
explain(). - ❌ Using text index for partial searches with regex —
^wordqueries don't benefit from text indexes.
📊 Simple Benchmark: With vs. Without Indexes
1. Simple Index on email Field
Without index:
db.clients.find({ email: "carlos.teste@example.com" }).explain("executionStats")
executionStats.totalDocsExamined: 1,000,000
executionTimeMillis: HighWith index:
db.clients.createIndex({ email: 1 })
db.clients.find({ email: "client987654@example.com" }).explain("executionStats")
executionStats.totalDocsExamined: 1
executionTimeMillis: Low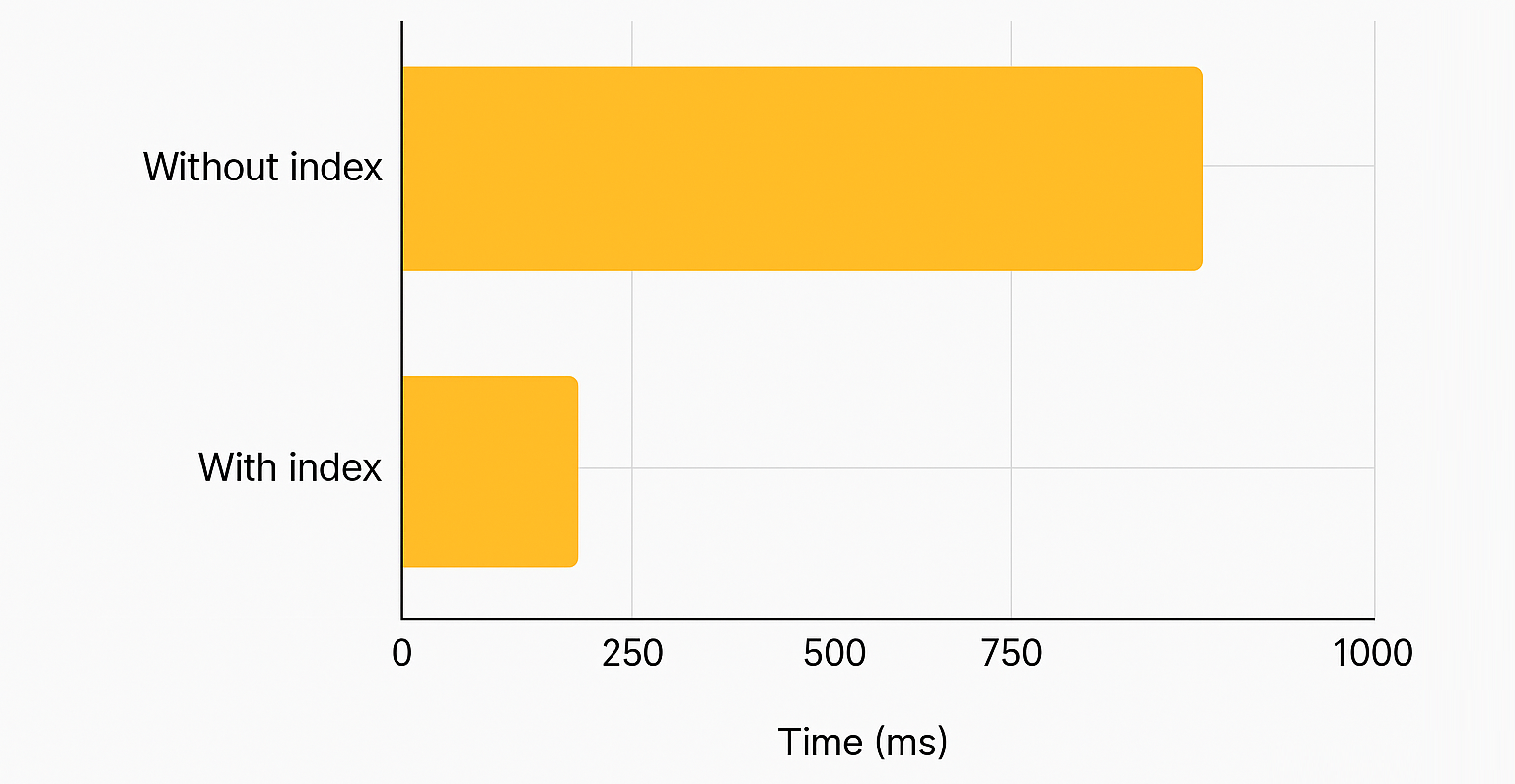
2. Poorly vs. Well-Planned Compound Index
Poorly planned index:
db.orders.createIndex({ status: 1, customer_id: 1 })
db.orders.find({ customer_id: "abc123" }) // ❌ index not usedCorrected index:
db.orders.createIndex({ customer_id: 1, status: 1 })
db.orders.find({ customer_id: "abc123" }) // ✅ index used=> Indexes and CPU Usage
- Each index increases write complexity (inserts/updates/deletes).
- Poorly designed indexes directly affect aggregation pipeline performance.
- Many aggregations requiring sort or lookup without indexes cause CPU spikes on the server.
- Use
db.currentOp()to investigate bottlenecks.
🚀 Conclusion
Indexes are essential for performance optimization but must be designed strategically. Poor indexing decisions can degrade your system's efficiency. Always analyze your application's query patterns before deciding on index configurations. Focus on:
- Real query patterns
- Data cardinality
- Impact on writes
- Analysis tools like
explain() - Want an agile and efficient system? Plan your indexes with the same care you plan your code.